
I have a fleeting thought whenever I sign up for a new service. I look at the login options (Facebook, Google, Apple, email) and think about what happens if I stop using any of those accounts someday. Then I create an email account anyway, which is a different fragility, and I move on.
The Facebook login question has gotten more interesting to me over time. The question just hadn’t occurred to me in 2008 when I was signing up for things. None of us did the math. Facebook was permanently the size it was and my account was permanently mine. The mental model of “digital accounts are forever” was so ambient it didn’t even register as a mental model.
Some people found out it wasn’t when their accounts got suspended. Some found out when they walked away from a platform and realized their data hadn’t come with them. The question “what actually happens to my digital life if a platform goes away, or if I do” turns out to be harder than it first appeared.
The part they solved first
The identity piece has been in active development for a while. OpenID Connect, the standard underneath most “sign in with Google/GitHub/Apple” buttons, defines authentication built on top of OAuth 2.0. It handles the gate: proving who you are so a service can let you in. That’s hard to do well, and it does it. Gmail login, GitHub login, Apple ID: all variants of the same idea. One credential, many doors.
What OpenID Connect specifies for those doors is identity claims: your name, email, profile. Once you’re in, the records you’ve built up inside the service stay there. Your Letterboxd watch history, your Goodreads shelves, your posts: those live wherever the platform keeps them. The credential got you in. The data you create once you’re in stays behind when you leave.
That’s the harder problem.

What the AT Protocol is trying to do
ATProto (the AT Protocol) started as the foundation for Bluesky, a decentralized social network. I started reading the specs expecting to find “it’s like Twitter but with a different company,” and instead found something I’ve been turning over for a few months.
The core idea: your identity (a DID, a decentralized identifier) is yours to keep and move, and the records you create on the network live on a Personal Data Server you control. Applications read from and write to a shared network rather than private databases they own. The portability is structural, baked into the architecture rather than added on top.
A few things worth being precise about. ATProto handles structured social records well: posts, follows, lists, the relational fabric of online interaction. It also supports media blobs, with images and video stored on your PDS and associated with your DID. The serving story is more complicated: blobs get delivered through application-layer CDNs rather than directly from the PDS, and PDS operators set their own storage quotas and size limits. The design is oriented around media attached to social records, not a general-purpose file system. Using it as a drop-in for Google Photos or Dropbox is a stretch. For media that lives inside a social context, the portability holds. It’s also early, which means the ecosystem has rough edges, and I’m learning by building rather than reading from a finished manual.
In late March, the IETF formally approved an ATP working group. HTTP went through IETF. SMTP went through IETF. I find it interesting that a protocol at this stage is already in that process, though I’m watching rather than predicting.
The harder question, still being answered
The current version of ATProto handles public records well. Private groups, personal notes, data you want to share with specific people rather than everyone: that part is still being worked out.
Earlier this year, the ATProto team published a design for it. They’re calling it permissioned data. The approach uses “permission spaces” as authorization and sync boundaries, where access is governed through short-lived cryptographic credentials, records still live on each user’s own PDS, and the URI scheme for permissioned records will be distinct from public data (the current candidate is ats://). The spring roadmap marks it as a major focus through summer. Reading the design proposal, it has the feel of a document that had hard internal conversations before it became a post. Real tradeoffs named, not just the happy path.
So I built something on it
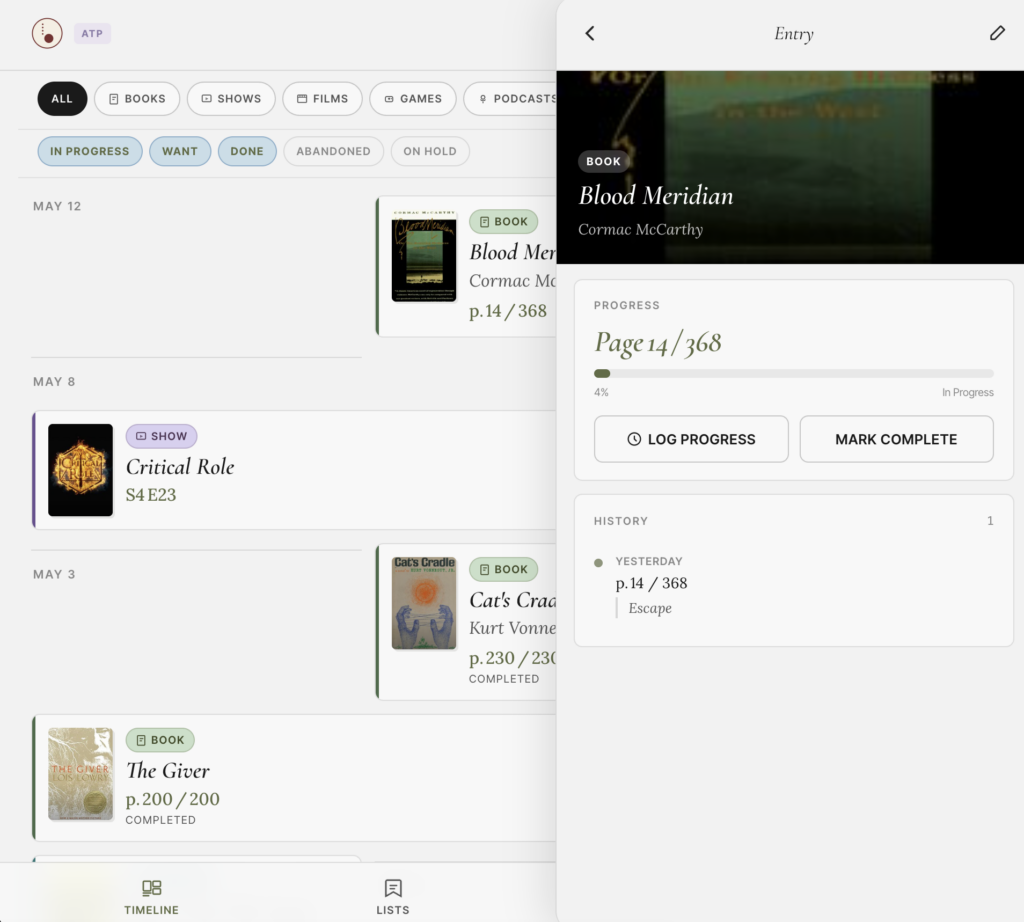
I have ADHD, and one of the ways that shows up practically is losing track of where I am in things. Books, shows, games, podcasts. I’ll pick something back up after a few weeks away and have no idea what happened last, or whether I even liked it enough to continue. I know a notepad exists. The problem is that a notepad requires remembering to update it, which is the precise category of thing I’m bad at.
A few months ago I built Breadcrumbs, a small media tracking app. I built it on ATProto partly to learn the protocol by actually building something, and partly because data portability felt right for the problem. The tracking data lives on my DID. If I stop maintaining the app, the records stay where they are, because that’s how the protocol works.
It’s early, and I put it out there because waiting until it’s done is how things don’t ship.
The permissioned data work is the part I’m most curious to watch, because that’s where apps like Breadcrumbs start to get more interesting. Shared lists, synced progress, small groups with shared context, without a centralized service sitting in the middle. That’s still on the roadmap. Building toward something feels more interesting than waiting for it to arrive.
Everything else
ATProto is one thread. There are people working on the neighboring questions, and I follow all of them with similar curiosity.
Ollama and the ecosystem around Hugging Face have made it practical to run capable AI models on your own hardware. The AI question turns out to be structurally similar to the data question: who controls the inference, who sees what goes in and what comes out, what happens when the vendor changes the terms. Meshtastic is doing something related for networking, building mesh radio infrastructure that works outside the cellular grid. The DWeb network has been gathering the broader community (storage, publishing, protocol work, everything that doesn’t fit neatly in a single project) since 2016.
None of it is a finished answer. All of it is the same question from a different angle.
I still sign up for things with email when I can. I’m still thinking about what the fully distributed version of my digital life looks like. But the Facebook login question feels less like a structural feature of how the internet works and more like a design decision someone made in the mid-2000s that we’re still renegotiating.
The renegotiation looks like: boring protocol work, IETF working groups, open-source tooling, people building small useful things on top of specs most of their users will never read. That’s how HTTP worked. That’s how email worked. From the outside, it’s not a compelling origin story. From the inside, it’s actually kind of interesting to be poking at.